 Data Science
Data ScienceChapter 2 Reading in data locally and from the web
2.1 Overview
In this chapter, you’ll learn to read tabular data of various formats into R from your local device (e.g., your laptop) and the web. “Reading” (or “loading”) is the process of converting data (stored as plain text, a database, HTML, etc.) into an object (e.g., a data frame) that R can easily access and manipulate. Thus reading data is the gateway to any data analysis; you won’t be able to analyze data unless you’ve loaded it first. And because there are many ways to store data, there are similarly many ways to read data into R. The more time you spend upfront matching the data reading method to the type of data you have, the less time you will have to devote to re-formatting, cleaning and wrangling your data (the second step to all data analyses). It’s like making sure your shoelaces are tied well before going for a run so that you don’t trip later on!
2.2 Chapter learning objectives
By the end of the chapter, readers will be able to do the following:
- Define the types of path and use them to locate files:
- absolute file path
- relative file path
- Uniform Resource Locator (URL)
- Read data into R from various types of path using:
read_csvread_tsvread_csv2read_delimread_excel
- Compare and contrast the
read_*functions. - Describe when to use the following
read_*function arguments:skipdelimcol_names
- Choose the appropriate
tidyverseread_*function and function arguments to load a given plain text tabular data set into R. - Use the
renamefunction to rename columns in a data frame. - Use
read_excelfunction and arguments to load a sheet from an excel file into R. - Work with databases using functions from
dbplyrandDBI:- Connect to a database with
dbConnect. - List tables in the database with
dbListTables. - Create a reference to a database table with
tbl. - Bring data from a database into R using
collect.
- Connect to a database with
- Use
write_csvto save a data frame to a.csvfile. - (Optional) Obtain data from the web using scraping and application programming interfaces (APIs):
- Read HTML source code from a URL using the
rvestpackage. - Read data from the NASA “Astronomy Picture of the Day” API using the
httr2package. - Compare downloading tabular data from a plain text file (e.g.,
.csv), accessing data from an API, and scraping the HTML source code from a website.
- Read HTML source code from a URL using the
2.3 Absolute and relative file paths
This chapter will discuss the different functions we can use to import data into R, but before we can talk about how we read the data into R with these functions, we first need to talk about where the data lives. When you load a data set into R, you first need to tell R where those files live. The file could live on your computer (local) or somewhere on the internet (remote).
The place where the file lives on your computer is referred to as its “path”. You can think of the path as directions to the file. There are two kinds of paths: relative paths and absolute paths. A relative path indicates where the file is with respect to your working directory (i.e., “where you are currently”) on the computer. On the other hand, an absolute path indicates where the file is with respect to the computer’s filesystem base (or root) folder, regardless of where you are working.
Suppose our computer’s filesystem looks like the picture in Figure
2.1. We are working in a
file titled project3.ipynb, and our current working directory is project3;
typically, as is the case here, the working directory is the directory containing the file you are currently
working on.
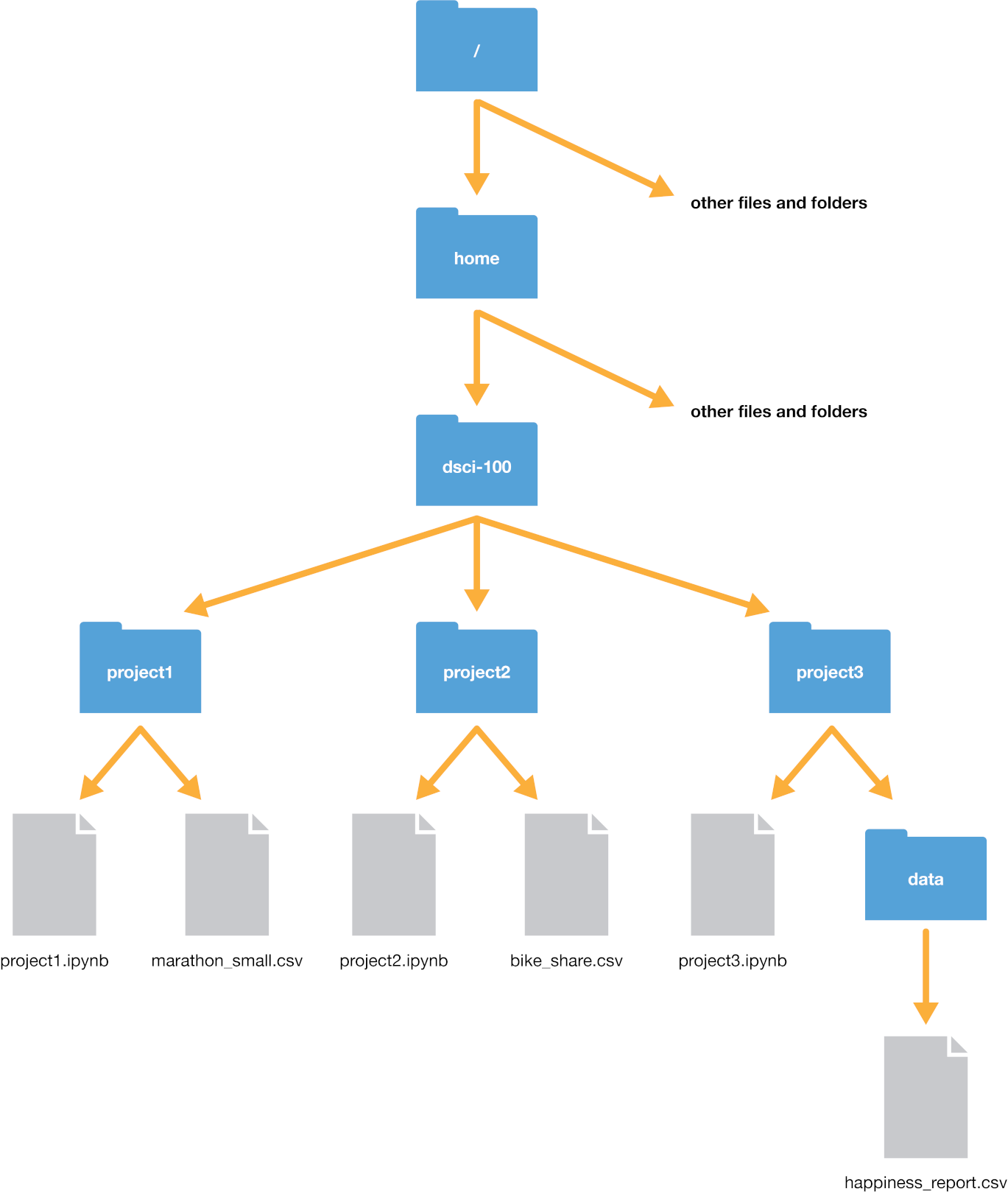
Figure 2.1: Example file system.
Let’s say we wanted to open the happiness_report.csv file. We have two options to indicate
where the file is: using a relative path, or using an absolute path.
The absolute path of the file always starts with a slash /—representing the root folder on the computer—and
proceeds by listing out the sequence of folders you would have to enter to reach the file, each separated by another slash /.
So in this case, happiness_report.csv would be reached by starting at the root, and entering the home folder,
then the dsci-100 folder, then the project3 folder, and then finally the data folder. So its absolute
path would be /home/dsci-100/project3/data/happiness_report.csv. We can load the file using its absolute path
as a string passed to the read_csv function.
If we instead wanted to use a relative path, we would need to list out the sequence of steps needed to get from our current
working directory to the file, with slashes / separating each step. Since we are currently in the project3 folder,
we just need to enter the data folder to reach our desired file. Hence the relative path is data/happiness_report.csv,
and we can load the file using its relative path as a string passed to read_csv.
Note that there is no forward slash at the beginning of a relative path; if we accidentally typed "/data/happiness_report.csv",
R would look for a folder named data in the root folder of the computer—but that doesn’t exist!
Aside from specifying places to go in a path using folder names (like data and project3), we can also specify two additional
special places: the current directory and the previous directory.
We indicate the current working directory with a single dot ., and
the previous directory with two dots ... So for instance, if we wanted to reach the bike_share.csv file from the project3 folder, we could
use the relative path ../project2/bike_share.csv. We can even combine these two; for example, we could reach the bike_share.csv file using
the (very silly) path ../project2/../project2/./bike_share.csv with quite a few redundant directions: it says to go back a folder, then open project2,
then go back a folder again, then open project2 again, then stay in the current directory, then finally get to bike_share.csv. Whew, what a long trip!
So which kind of path should you use: relative, or absolute? Generally speaking, you should use relative paths.
Using a relative path helps ensure that your code can be run
on a different computer (and as an added bonus, relative paths are often shorter—easier to type!).
This is because a file’s relative path is often the same across different computers, while a
file’s absolute path (the names of
all of the folders between the computer’s root, represented by /, and the file) isn’t usually the same
across different computers. For example, suppose Fatima and Jayden are working on a
project together on the happiness_report.csv data. Fatima’s file is stored at
/home/Fatima/project3/data/happiness_report.csv,
while Jayden’s is stored at
/home/Jayden/project3/data/happiness_report.csv.
Even though Fatima and Jayden stored their files in the same place on their
computers (in their home folders), the absolute paths are different due to
their different usernames. If Jayden has code that loads the
happiness_report.csv data using an absolute path, the code won’t work on
Fatima’s computer. But the relative path from inside the project3 folder
(data/happiness_report.csv) is the same on both computers; any code that uses
relative paths will work on both! In the additional resources section,
we include a link to a short video on the
difference between absolute and relative paths. You can also check out the
here package, which provides methods for finding and constructing file paths
in R.
Beyond files stored on your computer (i.e., locally), we also need a way to locate resources
stored elsewhere on the internet (i.e., remotely). For this purpose we use a
Uniform Resource Locator (URL), i.e., a web address that looks something
like https://datasciencebook.ca/. URLs indicate the location of a resource on the internet, and
start with a web domain, followed by a forward slash /, and then a path
to where the resource is located on the remote machine.
2.4 Reading tabular data from a plain text file into R
2.4.1 read_csv to read in comma-separated values files
Now that we have learned about where data could be, we will learn about how
to import data into R using various functions. Specifically, we will learn how
to read tabular data from a plain text file (a document containing only text)
into R and write tabular data to a file out of R. The function we use to do this
depends on the file’s format. For example, in the last chapter, we learned about using
the tidyverse read_csv function when reading .csv (comma-separated values)
files. In that case, the separator or delimiter that divided our columns was a
comma (,). We only learned the case where the data matched the expected defaults
of the read_csv function
(column names are present, and commas are used as the delimiter between columns).
In this section, we will learn how to read
files that do not satisfy the default expectations of read_csv.
Before we jump into the cases where the data aren’t in the expected default format
for tidyverse and read_csv, let’s revisit the more straightforward
case where the defaults hold, and the only argument we need to give to the function
is the path to the file, data/can_lang.csv. The can_lang data set contains
language data from the 2016 Canadian census.
We put data/ before the file’s
name when we are loading the data set because this data set is located in a
sub-folder, named data, relative to where we are running our R code.
Here is what the text in the file data/can_lang.csv looks like.
category,language,mother_tongue,most_at_home,most_at_work,lang_known
Aboriginal languages,"Aboriginal languages, n.o.s.",590,235,30,665
Non-Official & Non-Aboriginal languages,Afrikaans,10260,4785,85,23415
Non-Official & Non-Aboriginal languages,"Afro-Asiatic languages, n.i.e.",1150,44
Non-Official & Non-Aboriginal languages,Akan (Twi),13460,5985,25,22150
Non-Official & Non-Aboriginal languages,Albanian,26895,13135,345,31930
Aboriginal languages,"Algonquian languages, n.i.e.",45,10,0,120
Aboriginal languages,Algonquin,1260,370,40,2480
Non-Official & Non-Aboriginal languages,American Sign Language,2685,3020,1145,21
Non-Official & Non-Aboriginal languages,Amharic,22465,12785,200,33670And here is a review of how we can use read_csv to load it into R. First we
load the tidyverse package to gain access to useful
functions for reading the data.
Next we use read_csv to load the data into R, and in that call we specify the
relative path to the file. Note that it is normal and expected that a message is
printed out after using the read_csv and related functions. This message lets you know the data types
of each of the columns that R inferred while reading the data into R. In the
future when we use this and related functions to load data in this book, we will
silence these messages to help with the readability of the book.
## Rows: 214 Columns: 6
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): category, language
## dbl (4): mother_tongue, most_at_home, most_at_work, lang_known
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Finally, to view the first 10 rows of the data frame, we must call it:
## # A tibble: 214 × 6
## category language mother_tongue most_at_home most_at_work lang_known
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Aboriginal langu… Aborigi… 590 235 30 665
## 2 Non-Official & N… Afrikaa… 10260 4785 85 23415
## 3 Non-Official & N… Afro-As… 1150 445 10 2775
## 4 Non-Official & N… Akan (T… 13460 5985 25 22150
## 5 Non-Official & N… Albanian 26895 13135 345 31930
## 6 Aboriginal langu… Algonqu… 45 10 0 120
## 7 Aboriginal langu… Algonqu… 1260 370 40 2480
## 8 Non-Official & N… America… 2685 3020 1145 21930
## 9 Non-Official & N… Amharic 22465 12785 200 33670
## 10 Non-Official & N… Arabic 419890 223535 5585 629055
## # ℹ 204 more rows2.4.2 Skipping rows when reading in data
Oftentimes, information about how data was collected, or other relevant information, is included at the top of the data file. This information is usually written in sentence and paragraph form, with no delimiter because it is not organized into columns. An example of this is shown below. This information gives the data scientist useful context and information about the data, however, it is not well formatted or intended to be read into a data frame cell along with the tabular data that follows later in the file.
Data source: https://ttimbers.github.io/canlang/
Data originally published in: Statistics Canada Census of Population 2016.
Reproduced and distributed on an as-is basis with their permission.
category,language,mother_tongue,most_at_home,most_at_work,lang_known
Aboriginal languages,"Aboriginal languages, n.o.s.",590,235,30,665
Non-Official & Non-Aboriginal languages,Afrikaans,10260,4785,85,23415
Non-Official & Non-Aboriginal languages,"Afro-Asiatic languages, n.i.e.",1150,44
Non-Official & Non-Aboriginal languages,Akan (Twi),13460,5985,25,22150
Non-Official & Non-Aboriginal languages,Albanian,26895,13135,345,31930
Aboriginal languages,"Algonquian languages, n.i.e.",45,10,0,120
Aboriginal languages,Algonquin,1260,370,40,2480
Non-Official & Non-Aboriginal languages,American Sign Language,2685,3020,1145,21
Non-Official & Non-Aboriginal languages,Amharic,22465,12785,200,33670With this extra information being present at the top of the file, using
read_csv as we did previously does not allow us to correctly load the data
into R. In the case of this file we end up only reading in one column of the
data set. In contrast to the normal and expected messages above, this time R
prints out a warning for us indicating that there might be a problem with how
our data is being read in.
## Warning: One or more parsing issues, call `problems()` on your data frame for details,
## e.g.:
## dat <- vroom(...)
## problems(dat)## # A tibble: 217 × 1
## `Data source: https://ttimbers.github.io/canlang/`
## <chr>
## 1 "Data originally published in: Statistics Canada Census of Population 2016."
## 2 "Reproduced and distributed on an as-is basis with their permission."
## 3 "category,language,mother_tongue,most_at_home,most_at_work,lang_known"
## 4 "Aboriginal languages,\"Aboriginal languages, n.o.s.\",590,235,30,665"
## 5 "Non-Official & Non-Aboriginal languages,Afrikaans,10260,4785,85,23415"
## 6 "Non-Official & Non-Aboriginal languages,\"Afro-Asiatic languages, n.i.e.\",…
## 7 "Non-Official & Non-Aboriginal languages,Akan (Twi),13460,5985,25,22150"
## 8 "Non-Official & Non-Aboriginal languages,Albanian,26895,13135,345,31930"
## 9 "Aboriginal languages,\"Algonquian languages, n.i.e.\",45,10,0,120"
## 10 "Aboriginal languages,Algonquin,1260,370,40,2480"
## # ℹ 207 more rowsTo successfully read data like this into R, the skip
argument can be useful to tell R
how many lines to skip before
it should start reading in the data. In the example above, we would set this
value to 3.
## # A tibble: 214 × 6
## category language mother_tongue most_at_home most_at_work lang_known
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Aboriginal langu… Aborigi… 590 235 30 665
## 2 Non-Official & N… Afrikaa… 10260 4785 85 23415
## 3 Non-Official & N… Afro-As… 1150 445 10 2775
## 4 Non-Official & N… Akan (T… 13460 5985 25 22150
## 5 Non-Official & N… Albanian 26895 13135 345 31930
## 6 Aboriginal langu… Algonqu… 45 10 0 120
## 7 Aboriginal langu… Algonqu… 1260 370 40 2480
## 8 Non-Official & N… America… 2685 3020 1145 21930
## 9 Non-Official & N… Amharic 22465 12785 200 33670
## 10 Non-Official & N… Arabic 419890 223535 5585 629055
## # ℹ 204 more rowsHow did we know to skip three lines? We looked at the data! The first three lines of the data had information we didn’t need to import:
Data source: https://ttimbers.github.io/canlang/
Data originally published in: Statistics Canada Census of Population 2016.
Reproduced and distributed on an as-is basis with their permission.The column names began at line 4, so we skipped the first three lines.
2.4.3 read_tsv to read in tab-separated values files
Another common way data is stored is with tabs as the delimiter. Notice the
data file, can_lang.tsv, has tabs in between the columns instead of
commas.
category language mother_tongue most_at_home most_at_work lang_kno
Aboriginal languages Aboriginal languages, n.o.s. 590 235 30 665
Non-Official & Non-Aboriginal languages Afrikaans 10260 4785 85 23415
Non-Official & Non-Aboriginal languages Afro-Asiatic languages, n.i.e. 1150
Non-Official & Non-Aboriginal languages Akan (Twi) 13460 5985 25 22150
Non-Official & Non-Aboriginal languages Albanian 26895 13135 345 31930
Aboriginal languages Algonquian languages, n.i.e. 45 10 0 120
Aboriginal languages Algonquin 1260 370 40 2480
Non-Official & Non-Aboriginal languages American Sign Language 2685 3020
Non-Official & Non-Aboriginal languages Amharic 22465 12785 200 33670We can use the read_tsv function
to read in .tsv (tab separated values) files.
## # A tibble: 214 × 6
## category language mother_tongue most_at_home most_at_work lang_known
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Aboriginal langu… Aborigi… 590 235 30 665
## 2 Non-Official & N… Afrikaa… 10260 4785 85 23415
## 3 Non-Official & N… Afro-As… 1150 445 10 2775
## 4 Non-Official & N… Akan (T… 13460 5985 25 22150
## 5 Non-Official & N… Albanian 26895 13135 345 31930
## 6 Aboriginal langu… Algonqu… 45 10 0 120
## 7 Aboriginal langu… Algonqu… 1260 370 40 2480
## 8 Non-Official & N… America… 2685 3020 1145 21930
## 9 Non-Official & N… Amharic 22465 12785 200 33670
## 10 Non-Official & N… Arabic 419890 223535 5585 629055
## # ℹ 204 more rowsIf you compare the data frame here to the data frame we obtained in Section
2.4.1 using read_csv, you’ll notice that they look identical:
they have the same number of columns and rows, the same column names, and the same entries! So
even though we needed to use a different
function depending on the file format, our resulting data frame
(canlang_data) in both cases was the same.
2.4.4 read_delim as a more flexible method to get tabular data into R
The read_csv and read_tsv functions are actually just special cases of the more general
read_delim function. We can use
read_delim to import both comma and tab-separated values files, and more; we just
have to specify the delimiter.
For example, the can_lang_no_names.tsv file contains a different version of
this same data set with no column names and uses tabs as the delimiter
instead of commas.
Here is how the file would look in a plain text editor:
Aboriginal languages Aboriginal languages, n.o.s. 590 235 30 665
Non-Official & Non-Aboriginal languages Afrikaans 10260 4785 85 23415
Non-Official & Non-Aboriginal languages Afro-Asiatic languages, n.i.e. 1150
Non-Official & Non-Aboriginal languages Akan (Twi) 13460 5985 25 22150
Non-Official & Non-Aboriginal languages Albanian 26895 13135 345 31930
Aboriginal languages Algonquian languages, n.i.e. 45 10 0 120
Aboriginal languages Algonquin 1260 370 40 2480
Non-Official & Non-Aboriginal languages American Sign Language 2685 3020
Non-Official & Non-Aboriginal languages Amharic 22465 12785 200 33670
Non-Official & Non-Aboriginal languages Arabic 419890 223535 5585 629055To read this into R using the read_delim function, we specify the path
to the file as the first argument, provide
the tab character "\t" as the delim argument,
and set the col_names argument to FALSE to denote that there are no column names
provided in the data. Note that the read_csv, read_tsv, and read_delim functions
all have a col_names argument with
the default value TRUE.
Note:
\tis an example of an escaped character, which always starts with a backslash (\). Escaped characters are used to represent non-printing characters (like the tab) or those with special meanings (such as quotation marks).
canlang_data <- read_delim("data/can_lang_no_names.tsv",
delim = "\t",
col_names = FALSE)
canlang_data## # A tibble: 214 × 6
## X1 X2 X3 X4 X5 X6
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Aboriginal languages Aborigina… 590 235 30 665
## 2 Non-Official & Non-Aboriginal languages Afrikaans 10260 4785 85 23415
## 3 Non-Official & Non-Aboriginal languages Afro-Asia… 1150 445 10 2775
## 4 Non-Official & Non-Aboriginal languages Akan (Twi) 13460 5985 25 22150
## 5 Non-Official & Non-Aboriginal languages Albanian 26895 13135 345 31930
## 6 Aboriginal languages Algonquia… 45 10 0 120
## 7 Aboriginal languages Algonquin 1260 370 40 2480
## 8 Non-Official & Non-Aboriginal languages American … 2685 3020 1145 21930
## 9 Non-Official & Non-Aboriginal languages Amharic 22465 12785 200 33670
## 10 Non-Official & Non-Aboriginal languages Arabic 419890 223535 5585 629055
## # ℹ 204 more rowsData frames in R need to have column names. Thus if you read in data
without column names, R will assign names automatically. In this example,
R assigns the column names X1, X2, X3, X4, X5, X6.
It is best to rename your columns manually in this scenario. The current
column names (X1, X2, etc.) are not very descriptive and will make your analysis confusing.
To rename your columns, you can use the rename function
from the dplyr R package (Wickham, François, et al. 2021)
(one of the packages
loaded with tidyverse, so we don’t need to load it separately). The first
argument is the data set, and in the subsequent arguments you
write new_name = old_name for the selected variables to
rename. We rename the X1, X2, ..., X6
columns in the canlang_data data frame to more descriptive names below.
canlang_data <- rename(canlang_data,
category = X1,
language = X2,
mother_tongue = X3,
most_at_home = X4,
most_at_work = X5,
lang_known = X6)
canlang_data## # A tibble: 214 × 6
## category language mother_tongue most_at_home most_at_work lang_known
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Aboriginal langu… Aborigi… 590 235 30 665
## 2 Non-Official & N… Afrikaa… 10260 4785 85 23415
## 3 Non-Official & N… Afro-As… 1150 445 10 2775
## 4 Non-Official & N… Akan (T… 13460 5985 25 22150
## 5 Non-Official & N… Albanian 26895 13135 345 31930
## 6 Aboriginal langu… Algonqu… 45 10 0 120
## 7 Aboriginal langu… Algonqu… 1260 370 40 2480
## 8 Non-Official & N… America… 2685 3020 1145 21930
## 9 Non-Official & N… Amharic 22465 12785 200 33670
## 10 Non-Official & N… Arabic 419890 223535 5585 629055
## # ℹ 204 more rows2.4.5 Reading tabular data directly from a URL
We can also use read_csv, read_tsv, or read_delim (and related functions)
to read in data directly from a Uniform Resource Locator (URL) that
contains tabular data. Here, we provide the URL of a remote file to
read_*, instead of a path to a local file on our
computer. We need to surround the URL with quotes similar to when we specify a
path on our local computer. All other arguments that we use are the same as
when using these functions with a local file on our computer.
url <- "https://raw.githubusercontent.com/UBC-DSCI/data/main/can_lang.csv"
canlang_data <- read_csv(url)
canlang_data## # A tibble: 214 × 6
## category language mother_tongue most_at_home most_at_work lang_known
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Aboriginal langu… Aborigi… 590 235 30 665
## 2 Non-Official & N… Afrikaa… 10260 4785 85 23415
## 3 Non-Official & N… Afro-As… 1150 445 10 2775
## 4 Non-Official & N… Akan (T… 13460 5985 25 22150
## 5 Non-Official & N… Albanian 26895 13135 345 31930
## 6 Aboriginal langu… Algonqu… 45 10 0 120
## 7 Aboriginal langu… Algonqu… 1260 370 40 2480
## 8 Non-Official & N… America… 2685 3020 1145 21930
## 9 Non-Official & N… Amharic 22465 12785 200 33670
## 10 Non-Official & N… Arabic 419890 223535 5585 629055
## # ℹ 204 more rows2.4.6 Downloading data from a URL
Occasionally the data available at a URL is not formatted nicely enough to use
read_csv, read_tsv, read_delim, or other related functions to read the data
directly into R. In situations where it is necessary to download a file
to our local computer prior to working with it in R, we can use the download.file
function. The first argument is the URL, and the second is a path where we would
like to store the downloaded file.
## # A tibble: 214 × 6
## category language mother_tongue most_at_home most_at_work lang_known
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Aboriginal langu… Aborigi… 590 235 30 665
## 2 Non-Official & N… Afrikaa… 10260 4785 85 23415
## 3 Non-Official & N… Afro-As… 1150 445 10 2775
## 4 Non-Official & N… Akan (T… 13460 5985 25 22150
## 5 Non-Official & N… Albanian 26895 13135 345 31930
## 6 Aboriginal langu… Algonqu… 45 10 0 120
## 7 Aboriginal langu… Algonqu… 1260 370 40 2480
## 8 Non-Official & N… America… 2685 3020 1145 21930
## 9 Non-Official & N… Amharic 22465 12785 200 33670
## 10 Non-Official & N… Arabic 419890 223535 5585 629055
## # ℹ 204 more rows2.4.7 Previewing a data file before reading it into R
In many of the examples above, we gave you previews of the data file before we read it into R. Previewing data is essential to see whether or not there are column names, what the delimiters are, and if there are lines you need to skip. You should do this yourself when trying to read in data files: open the file in whichever text editor you prefer to inspect its contents prior to reading it into R.
2.5 Reading tabular data from a Microsoft Excel file
There are many other ways to store tabular data sets beyond plain text files,
and similarly, many ways to load those data sets into R. For example, it is
very common to encounter, and need to load into R, data stored as a Microsoft
Excel spreadsheet (with the file name
extension .xlsx). To be able to do this, a key thing to know is that even
though .csv and .xlsx files look almost identical when loaded into Excel,
the data themselves are stored completely differently. While .csv files are
plain text files, where the characters you see when you open the file in a text
editor are exactly the data they represent, this is not the case for .xlsx
files. Take a look at a snippet of what a .xlsx file would look like in a text editor:
,?'O
_rels/.rels???J1??>E?{7?
<?V????w8?'J???'QrJ???Tf?d??d?o?wZ'???@>?4'?|??hlIo??F
t 8f??3wn
????t??u"/
%~Ed2??<?w??
?Pd(??J-?E???7?'t(?-GZ?????y???c~N?g[^_r?4
yG?O
?K??G?
]TUEe??O??c[???????6q??s??d?m???\???H?^????3} ?rZY? ?:L60?^?????XTP+?|?
X?a??4VT?,D?JqThis type of file representation allows Excel files to store additional things
that you cannot store in a .csv file, such as fonts, text formatting,
graphics, multiple sheets and more. And despite looking odd in a plain text
editor, we can read Excel spreadsheets into R using the readxl package
developed specifically for this
purpose.
## # A tibble: 214 × 6
## category language mother_tongue most_at_home most_at_work lang_known
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Aboriginal langu… Aborigi… 590 235 30 665
## 2 Non-Official & N… Afrikaa… 10260 4785 85 23415
## 3 Non-Official & N… Afro-As… 1150 445 10 2775
## 4 Non-Official & N… Akan (T… 13460 5985 25 22150
## 5 Non-Official & N… Albanian 26895 13135 345 31930
## 6 Aboriginal langu… Algonqu… 45 10 0 120
## 7 Aboriginal langu… Algonqu… 1260 370 40 2480
## 8 Non-Official & N… America… 2685 3020 1145 21930
## 9 Non-Official & N… Amharic 22465 12785 200 33670
## 10 Non-Official & N… Arabic 419890 223535 5585 629055
## # ℹ 204 more rowsIf the .xlsx file has multiple sheets, you have to use the sheet argument
to specify the sheet number or name. You can also specify cell ranges using the
range argument. This functionality is useful when a single sheet contains
multiple tables (a sad thing that happens to many Excel spreadsheets since this
makes reading in data more difficult).
As with plain text files, you should always explore the data file before importing it into R. Exploring the data beforehand helps you decide which arguments you need to load the data into R successfully. If you do not have the Excel program on your computer, you can use other programs to preview the file. Examples include Google Sheets and Libre Office.
In Table 2.1 we summarize the read_* functions we covered
in this chapter. We also include the read_csv2 function for data separated by
semicolons ;, which you may run into with data sets where the decimal is
represented by a comma instead of a period (as with some data sets from
European countries).
| Data File Type | R Function | R Package |
|---|---|---|
Comma (,) separated files |
read_csv |
readr |
Tab (\t) separated files |
read_tsv |
readr |
Semicolon (;) separated files |
read_csv2 |
readr |
Various formats (.csv, .tsv) |
read_delim |
readr |
Excel files (.xlsx) |
read_excel |
readxl |
Note:
readris a part of thetidyversepackage so we did not need to load this package separately since we loadedtidyverse.
2.6 Reading data from a database
Another very common form of data storage is the relational database. Databases are great when you have large data sets or multiple users working on a project. There are many relational database management systems, such as SQLite, MySQL, PostgreSQL, Oracle, and many more. These different relational database management systems each have their own advantages and limitations. Almost all employ SQL (structured query language) to obtain data from the database. But you don’t need to know SQL to analyze data from a database; several packages have been written that allow you to connect to relational databases and use the R programming language to obtain data. In this book, we will give examples of how to do this using R with SQLite and PostgreSQL databases.
2.6.1 Reading data from a SQLite database
SQLite is probably the simplest relational database system
that one can use in combination with R. SQLite databases are self-contained, and are
usually stored and accessed locally on one computer from
a file with a .db extension (or sometimes an .sqlite extension).
Similar to Excel files, these are not plain text
files and cannot be read in a plain text editor.
The first thing you need to do to read data into R from a database is to
connect to the database. We do that using the dbConnect function from the
DBI (database interface) package. This does not read
in the data, but simply tells R where the database is and opens up a
communication channel that R can use to send SQL commands to the database.
Often relational databases have many tables; thus, in order to retrieve
data from a database, you need to know the name of the table
in which the data is stored. You can get the names of
all the tables in the database using the dbListTables
function:
## [1] "lang"The dbListTables function returned only one name, which tells us
that there is only one table in this database. To reference a table in the
database (so that we can perform operations like selecting columns and filtering rows), we
use the tbl function from the dbplyr package. The object returned
by the tbl function allows us to work with data
stored in databases as if they were just regular data frames; but secretly, behind
the scenes, dbplyr is turning your function calls (e.g., select and filter)
into SQL queries!
## # Source: table<lang> [?? x 6]
## # Database: sqlite 3.41.2 [/home/rstudio/introduction-to-datascience/data/can_lang.db]
## category language mother_tongue most_at_home most_at_work lang_known
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Aboriginal langu… Aborigi… 590 235 30 665
## 2 Non-Official & N… Afrikaa… 10260 4785 85 23415
## 3 Non-Official & N… Afro-As… 1150 445 10 2775
## 4 Non-Official & N… Akan (T… 13460 5985 25 22150
## 5 Non-Official & N… Albanian 26895 13135 345 31930
## 6 Aboriginal langu… Algonqu… 45 10 0 120
## 7 Aboriginal langu… Algonqu… 1260 370 40 2480
## 8 Non-Official & N… America… 2685 3020 1145 21930
## 9 Non-Official & N… Amharic 22465 12785 200 33670
## 10 Non-Official & N… Arabic 419890 223535 5585 629055
## # ℹ more rowsAlthough it looks like we just got a data frame from the database, we didn’t!
It’s a reference; the data is still stored only in the SQLite database. The
dbplyr package works this way because databases are often more efficient at selecting, filtering
and joining large data sets than R. And typically the database will not even
be stored on your computer, but rather a more powerful machine somewhere on the
web. So R is lazy and waits to bring this data into memory until you explicitly
tell it to using the collect function.
Figure 2.2 highlights the difference
between a tibble object in R and the output we just created. Notice in the table
on the right, the first two lines of the output indicate the source is SQL. The
last line doesn’t show how many rows there are (R is trying to avoid performing
expensive query operations), whereas the output for the tibble object does.
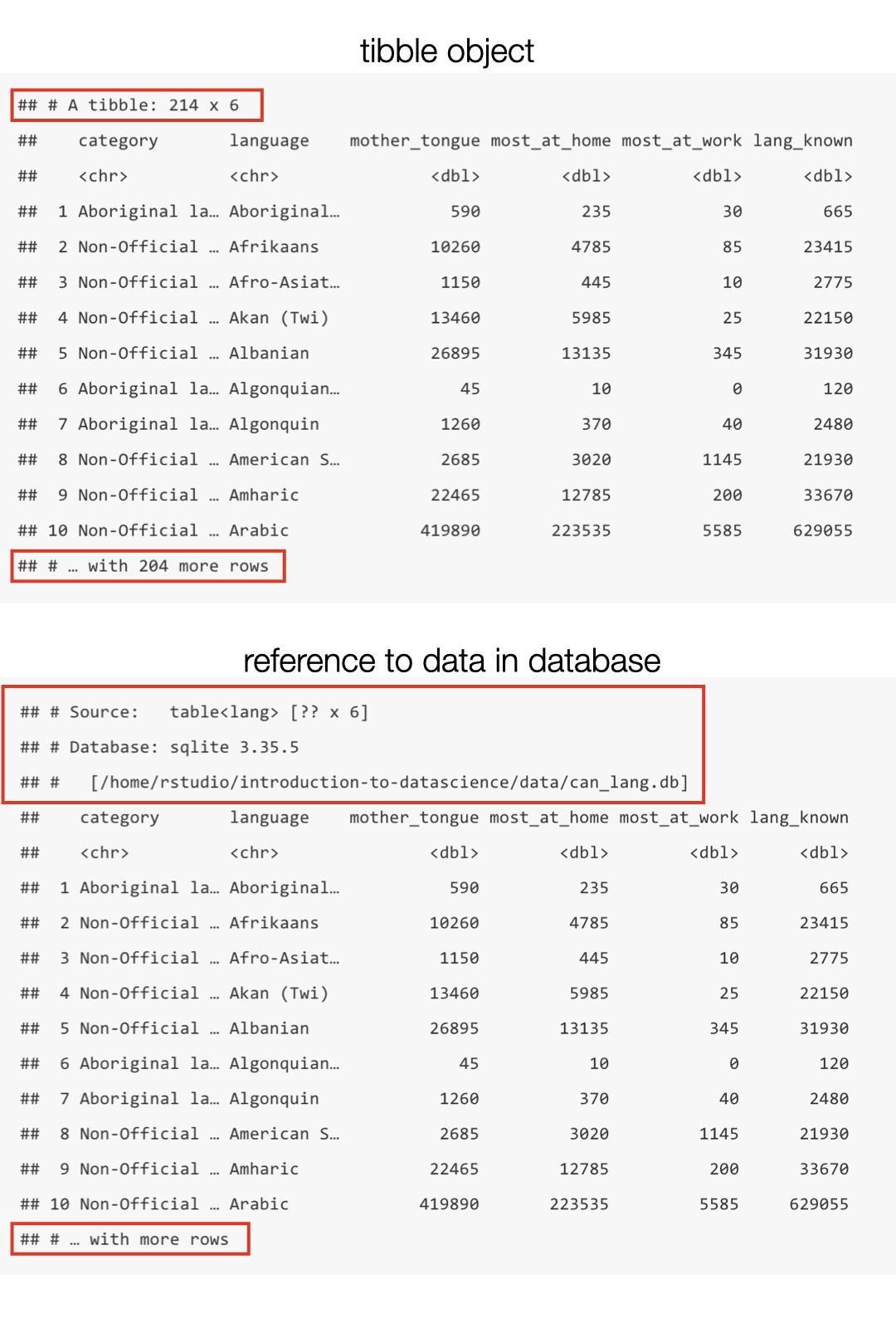
Figure 2.2: Comparison of a reference to data in a database and a tibble in R.
We can look at the SQL commands that are sent to the database when we write
tbl(canlang_conn, "lang") in R with the show_query function from the
dbplyr package.
## <SQL>
## SELECT *
## FROM `lang`The output above shows the SQL code that is sent to the database. When we
write tbl(canlang_conn, "lang") in R, in the background, the function is
translating the R code into SQL, sending that SQL to the database, and then translating the
response for us. So dbplyr does all the hard work of translating from R to SQL and back for us;
we can just stick with R!
With our lang_db table reference for the 2016 Canadian Census data in hand, we
can mostly continue onward as if it were a regular data frame. For example, let’s do the same exercise
from Chapter 1: we will obtain only those rows corresponding to Aboriginal languages, and keep only
the language and mother_tongue columns.
We can use the filter function to obtain only certain rows. Below we filter the data to include only Aboriginal languages.
## # Source: SQL [?? x 6]
## # Database: sqlite 3.41.2 [/home/rstudio/introduction-to-datascience/data/can_lang.db]
## category language mother_tongue most_at_home most_at_work lang_known
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Aboriginal langu… Aborigi… 590 235 30 665
## 2 Aboriginal langu… Algonqu… 45 10 0 120
## 3 Aboriginal langu… Algonqu… 1260 370 40 2480
## 4 Aboriginal langu… Athabas… 50 10 0 85
## 5 Aboriginal langu… Atikame… 6150 5465 1100 6645
## 6 Aboriginal langu… Babine … 110 20 10 210
## 7 Aboriginal langu… Beaver 190 50 0 340
## 8 Aboriginal langu… Blackfo… 2815 1110 85 5645
## 9 Aboriginal langu… Carrier 1025 250 15 2100
## 10 Aboriginal langu… Cayuga 45 10 10 125
## # ℹ more rowsAbove you can again see the hints that this data is not actually stored in R yet:
the source is SQL [?? x 6] and the output says ... more rows at the end
(both indicating that R does not know how many rows there are in total!),
and a database type sqlite is listed.
We didn’t use the collect function because we are not ready to bring the data into R yet.
We can still use the database to do some work to obtain only the small amount of data we want to work with locally
in R. Let’s add the second part of our database query: selecting only the language and mother_tongue columns
using the select function.
aboriginal_lang_selected_db <- select(aboriginal_lang_db, language, mother_tongue)
aboriginal_lang_selected_db## # Source: SQL [?? x 2]
## # Database: sqlite 3.41.2 [/home/rstudio/introduction-to-datascience/data/can_lang.db]
## language mother_tongue
## <chr> <dbl>
## 1 Aboriginal languages, n.o.s. 590
## 2 Algonquian languages, n.i.e. 45
## 3 Algonquin 1260
## 4 Athabaskan languages, n.i.e. 50
## 5 Atikamekw 6150
## 6 Babine (Wetsuwet'en) 110
## 7 Beaver 190
## 8 Blackfoot 2815
## 9 Carrier 1025
## 10 Cayuga 45
## # ℹ more rowsNow you can see that the database will return only the two columns we asked for with the select function.
In order to actually retrieve this data in R as a data frame,
we use the collect function.
Below you will see that after running collect, R knows that the retrieved
data has 67 rows, and there is no database listed any more.
## # A tibble: 67 × 2
## language mother_tongue
## <chr> <dbl>
## 1 Aboriginal languages, n.o.s. 590
## 2 Algonquian languages, n.i.e. 45
## 3 Algonquin 1260
## 4 Athabaskan languages, n.i.e. 50
## 5 Atikamekw 6150
## 6 Babine (Wetsuwet'en) 110
## 7 Beaver 190
## 8 Blackfoot 2815
## 9 Carrier 1025
## 10 Cayuga 45
## # ℹ 57 more rowsAside from knowing the number of rows, the data looks pretty similar in both
outputs shown above. And dbplyr provides many more functions (not just filter)
that you can use to directly feed the database reference (lang_db) into
downstream analysis functions (e.g., ggplot2 for data visualization).
But dbplyr does not provide every function that we need for analysis;
we do eventually need to call collect.
For example, look what happens when we try to use nrow to count rows
in a data frame:
## [1] NAor tail to preview the last six rows of a data frame:
## Error: tail() is not supported by sql sourcesAdditionally, some operations will not work to extract columns or single values
from the reference given by the tbl function. Thus, once you have finished
your data wrangling of the tbl database reference object, it is advisable to
bring it into R as a data frame using collect.
But be very careful using collect: databases are often very big,
and reading an entire table into R might take a long time to run or even possibly
crash your machine. So make sure you use filter and select on the database table
to reduce the data to a reasonable size before using collect to read it into R!
2.6.2 Reading data from a PostgreSQL database
PostgreSQL (also called Postgres) is a very popular
and open-source option for relational database software.
Unlike SQLite,
PostgreSQL uses a client–server database engine, as it was designed to be used
and accessed on a network. This means that you have to provide more information
to R when connecting to Postgres databases. The additional information that you
need to include when you call the dbConnect function is listed below:
dbname: the name of the database (a single PostgreSQL instance can host more than one database)host: the URL pointing to where the database is locatedport: the communication endpoint between R and the PostgreSQL database (usually5432)user: the username for accessing the databasepassword: the password for accessing the database
Additionally, we must use the RPostgres package instead of RSQLite in the
dbConnect function call. Below we demonstrate how to connect to a version of
the can_mov_db database, which contains information about Canadian movies.
Note that the host (fakeserver.stat.ubc.ca), user (user0001), and
password (abc123) below are not real; you will not actually
be able to connect to a database using this information.
library(RPostgres)
canmov_conn <- dbConnect(RPostgres::Postgres(), dbname = "can_mov_db",
host = "fakeserver.stat.ubc.ca", port = 5432,
user = "user0001", password = "abc123")After opening the connection, everything looks and behaves almost identically
to when we were using an SQLite database in R. For example, we can again use
dbListTables to find out what tables are in the can_mov_db database:
[1] "themes" "medium" "titles" "title_aliases" "forms"
[6] "episodes" "names" "names_occupations" "occupation" "ratings"We see that there are 10 tables in this database. Let’s first look at the
"ratings" table to find the lowest rating that exists in the can_mov_db
database:
# Source: table<ratings> [?? x 3]
# Database: postgres [user0001@fakeserver.stat.ubc.ca:5432/can_mov_db]
title average_rating num_votes
<chr> <dbl> <int>
1 The Grand Seduction 6.6 150
2 Rhymes for Young Ghouls 6.3 1685
3 Mommy 7.5 1060
4 Incendies 6.1 1101
5 Bon Cop, Bad Cop 7.0 894
6 Goon 5.5 1111
7 Monsieur Lazhar 5.6 610
8 What if 5.3 1401
9 The Barbarian Invations 5.8 99
10 Away from Her 6.9 2311
# … with more rowsTo find the lowest rating that exists in the data base, we first need to
extract the average_rating column using select:
# Source: lazy query [?? x 1]
# Database: postgres [user0001@fakeserver.stat.ubc.ca:5432/can_mov_db]
average_rating
<dbl>
1 6.6
2 6.3
3 7.5
4 6.1
5 7.0
6 5.5
7 5.6
8 5.3
9 5.8
10 6.9
# … with more rowsNext we use min to find the minimum rating in that column:
Error in min(avg_rating_db) : invalid 'type' (list) of argumentInstead of the minimum, we get an error! This is another example of when we
need to use the collect function to bring the data into R for further
computation:
[1] 1We see the lowest rating given to a movie is 1, indicating that it must have been a really bad movie…
2.6.3 Why should we bother with databases at all?
Opening a database
involved a lot more effort than just opening a .csv, .tsv, or any of the
other plain text or Excel formats. We had to open a connection to the database,
then use dbplyr to translate tidyverse-like
commands (filter, select etc.) into SQL commands that the database
understands, and then finally collect the results. And not
all tidyverse commands can currently be translated to work with
databases. For example, we can compute a mean with a database
but can’t easily compute a median. So you might be wondering: why should we use
databases at all?
Databases are beneficial in a large-scale setting:
- They enable storing large data sets across multiple computers with backups.
- They provide mechanisms for ensuring data integrity and validating input.
- They provide security and data access control.
- They allow multiple users to access data simultaneously
and remotely without conflicts and errors.
For example, there are billions of Google searches conducted daily in 2021 (Real Time Statistics Project 2021).
Can you imagine if Google stored all of the data
from those searches in a single
.csvfile!? Chaos would ensue!
2.7 Writing data from R to a .csv file
At the middle and end of a data analysis, we often want to write a data frame
that has changed (either through filtering, selecting, mutating or summarizing)
to a file to share it with others or use it for another step in the analysis.
The most straightforward way to do this is to use the write_csv function
from the tidyverse package. The default
arguments for this file are to use a comma (,) as the delimiter and include
column names. Below we demonstrate creating a new version of the Canadian
languages data set without the official languages category according to the
Canadian 2016 Census, and then writing this to a .csv file:
2.8 Obtaining data from the web
Note: This section is not required reading for the remainder of the textbook. It is included for those readers interested in learning a little bit more about how to obtain different types of data from the web.
Data doesn’t just magically appear on your computer; you need to get it from
somewhere. Earlier in the chapter we showed you how to access data stored in a
plain text, spreadsheet-like format (e.g., comma- or tab-separated) from a web
URL using one of the read_* functions from the tidyverse. But as time goes
on, it is increasingly uncommon to find data (especially large amounts of data)
in this format available for download from a URL. Instead, websites now often
offer something known as an application programming interface
(API), which
provides a programmatic way to ask for subsets of a data set. This allows the
website owner to control who has access to the data, what portion of the
data they have access to, and how much data they can access. Typically, the
website owner will give you a token or key (a secret string of characters somewhat
like a password) that you have to provide when accessing the API.
Another interesting thought: websites themselves are data! When you type a URL into your browser window, your browser asks the web server (another computer on the internet whose job it is to respond to requests for the website) to give it the website’s data, and then your browser translates that data into something you can see. If the website shows you some information that you’re interested in, you could create a data set for yourself by copying and pasting that information into a file. This process of taking information directly from what a website displays is called web scraping (or sometimes screen scraping). Now, of course, copying and pasting information manually is a painstaking and error-prone process, especially when there is a lot of information to gather. So instead of asking your browser to translate the information that the web server provides into something you can see, you can collect that data programmatically—in the form of hypertext markup language (HTML) and cascading style sheet (CSS) code—and process it to extract useful information. HTML provides the basic structure of a site and tells the webpage how to display the content (e.g., titles, paragraphs, bullet lists etc.), whereas CSS helps style the content and tells the webpage how the HTML elements should be presented (e.g., colors, layouts, fonts etc.).
This subsection will show you the basics of both web scraping
with the rvest R package (Wickham 2021a)
and accessing the NASA “Astronomy Picture of the Day” API
using the httr2 R package (Wickham 2023).
2.8.1 Web scraping
HTML and CSS selectors
When you enter a URL into your browser, your browser connects to the web server at that URL and asks for the source code for the website. This is the data that the browser translates into something you can see; so if we are going to create our own data by scraping a website, we have to first understand what that data looks like! For example, let’s say we are interested in knowing the average rental price (per square foot) of the most recently available one-bedroom apartments in Vancouver on Craiglist. When we visit the Vancouver Craigslist website and search for one-bedroom apartments, we should see something similar to Figure 2.3.
Figure 2.3: Craigslist webpage of advertisements for one-bedroom apartments.
Based on what our browser shows us, it’s pretty easy to find the size and price for each apartment listed. But we would like to be able to obtain that information using R, without any manual human effort or copying and pasting. We do this by examining the source code that the web server actually sent our browser to display for us. We show a snippet of it below; the entire source is included with the code for this book:
<span class="result-meta">
<span class="result-price">$800</span>
<span class="housing">
1br -
</span>
<span class="result-hood"> (13768 108th Avenue)</span>
<span class="result-tags">
<span class="maptag" data-pid="6786042973">map</span>
</span>
<span class="banish icon icon-trash" role="button">
<span class="screen-reader-text">hide this posting</span>
</span>
<span class="unbanish icon icon-trash red" role="button"></span>
<a href="#" class="restore-link">
<span class="restore-narrow-text">restore</span>
<span class="restore-wide-text">restore this posting</span>
</a>
<span class="result-price">$2285</span>
</span>Oof…you can tell that the source code for a web page is not really designed for humans to understand easily. However, if you look through it closely, you will find that the information we’re interested in is hidden among the muck. For example, near the top of the snippet above you can see a line that looks like
That snippet is definitely storing the price of a particular apartment. With some more investigation, you should be able to find things like the date and time of the listing, the address of the listing, and more. So this source code most likely contains all the information we are interested in!
Let’s dig into that line above a bit more. You can see that
that bit of code has an opening tag (words between < and >, like
<span>) and a closing tag (the same with a slash, like </span>). HTML
source code generally stores its data between opening and closing tags like
these. Tags are keywords that tell the web browser how to display or format
the content. Above you can see that the information we want ($800) is stored
between an opening and closing tag (<span> and </span>). In the opening
tag, you can also see a very useful “class” (a special word that is sometimes
included with opening tags): class="result-price". Since we want R to
programmatically sort through all of the source code for the website to find
apartment prices, maybe we can look for all the tags with the "result-price"
class, and grab the information between the opening and closing tag. Indeed,
take a look at another line of the source snippet above:
It’s yet another price for an apartment listing, and the tags surrounding it
have the "result-price" class. Wonderful! Now that we know what pattern we
are looking for—a dollar amount between opening and closing tags that have the
"result-price" class—we should be able to use code to pull out all of the
matching patterns from the source code to obtain our data. This sort of “pattern”
is known as a CSS selector (where CSS stands for cascading style sheet).
The above was a simple example of “finding the pattern to look for”; many
websites are quite a bit larger and more complex, and so is their website
source code. Fortunately, there are tools available to make this process
easier. For example,
SelectorGadget is
an open-source tool that simplifies identifying the generating
and finding of CSS selectors.
At the end of the chapter in the additional resources section, we include a link to
a short video on how to install and use the SelectorGadget tool to
obtain CSS selectors for use in web scraping.
After installing and enabling the tool, you can click the
website element for which you want an appropriate selector. For
example, if we click the price of an apartment listing, we
find that SelectorGadget shows us the selector .result-price
in its toolbar, and highlights all the other apartment
prices that would be obtained using that selector (Figure 2.4).
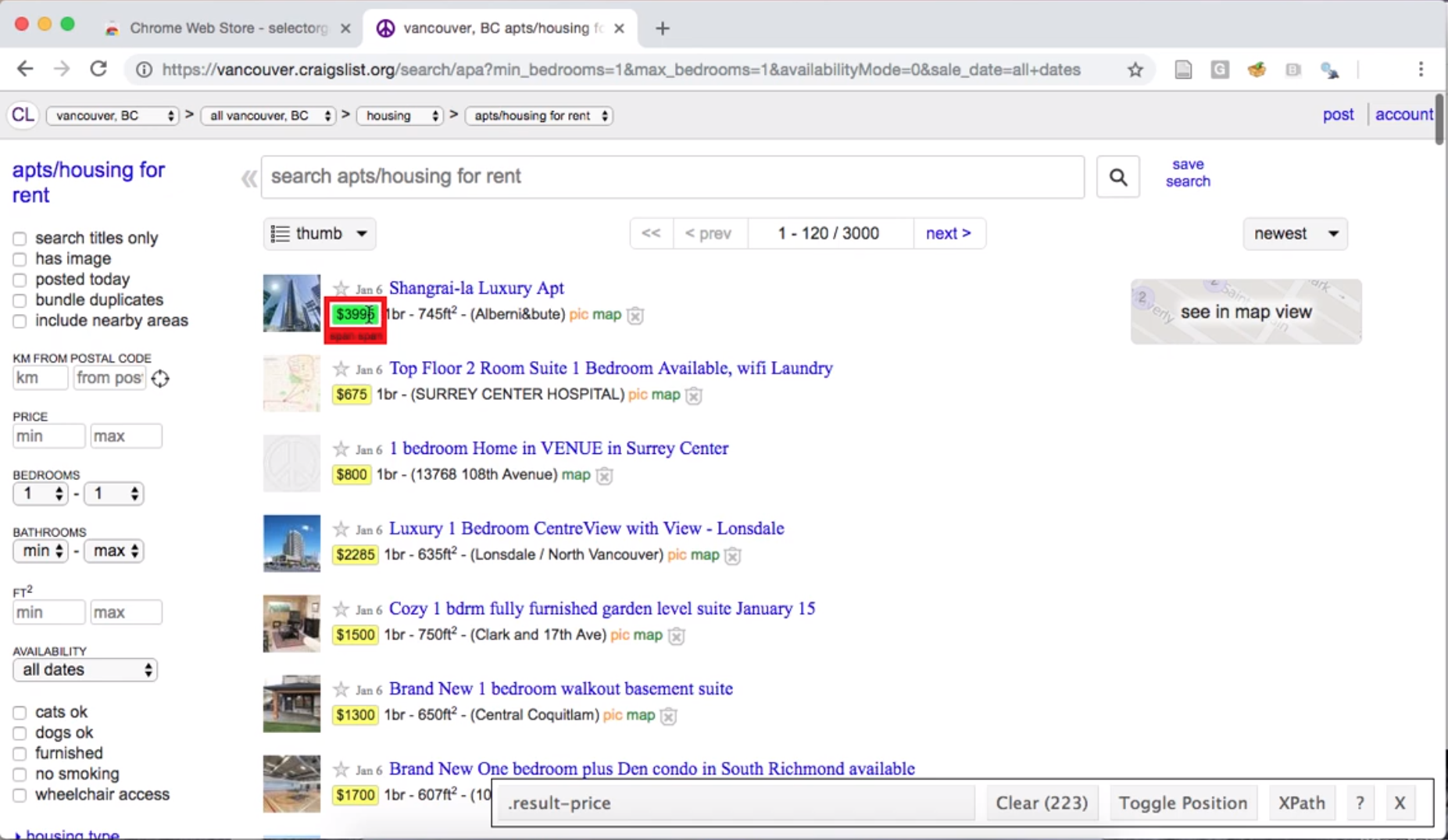
Figure 2.4: Using the SelectorGadget on a Craigslist webpage to obtain the CCS selector useful for obtaining apartment prices.
If we then click the size of an apartment listing, SelectorGadget shows us
the span selector, and highlights many of the lines on the page; this indicates that the
span selector is not specific enough to capture only apartment sizes (Figure 2.5).
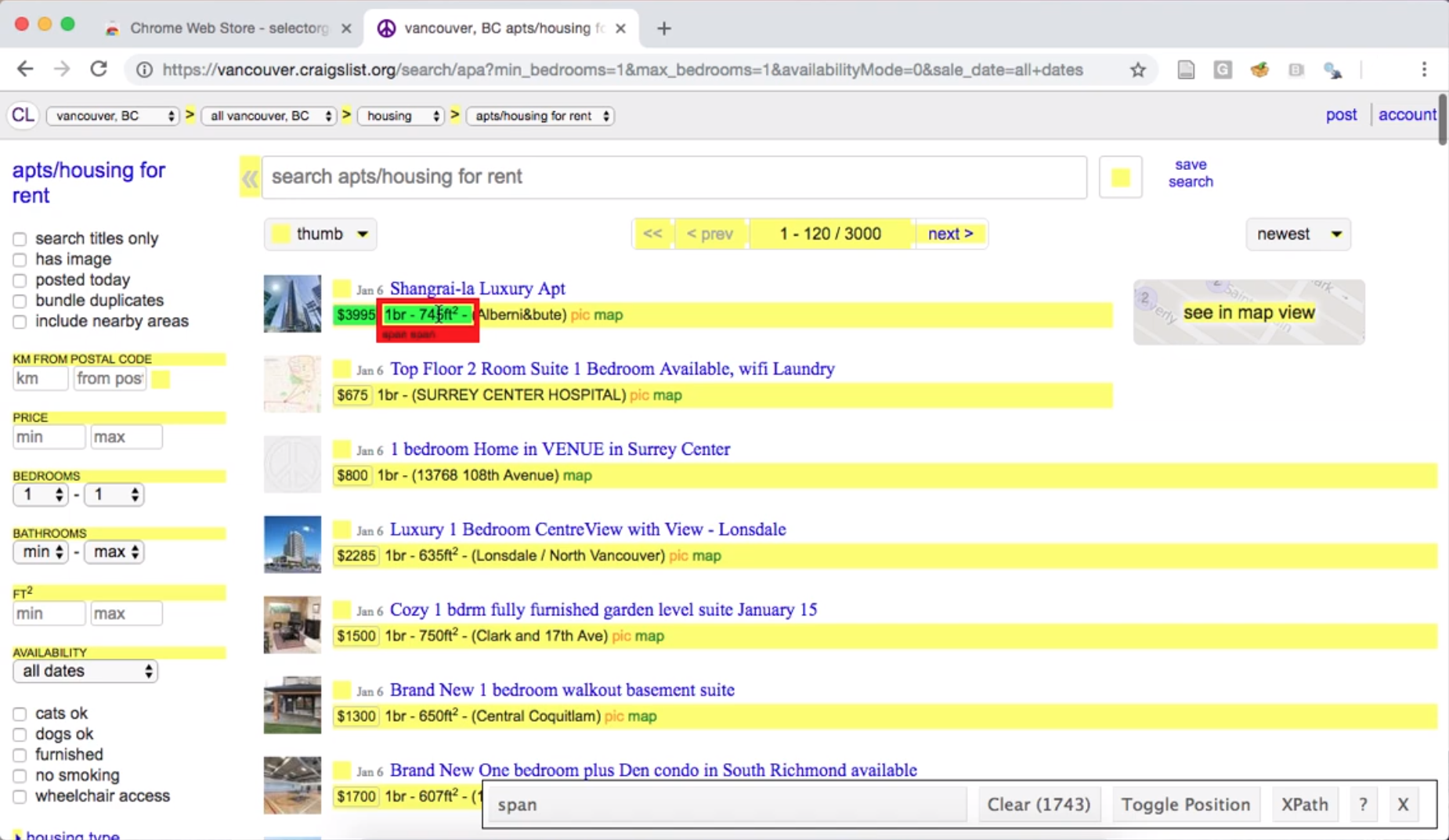
Figure 2.5: Using the SelectorGadget on a Craigslist webpage to obtain a CCS selector useful for obtaining apartment sizes.
To narrow the selector, we can click one of the highlighted elements that
we do not want. For example, we can deselect the “pic/map” links,
resulting in only the data we want highlighted using the .housing selector (Figure 2.6).
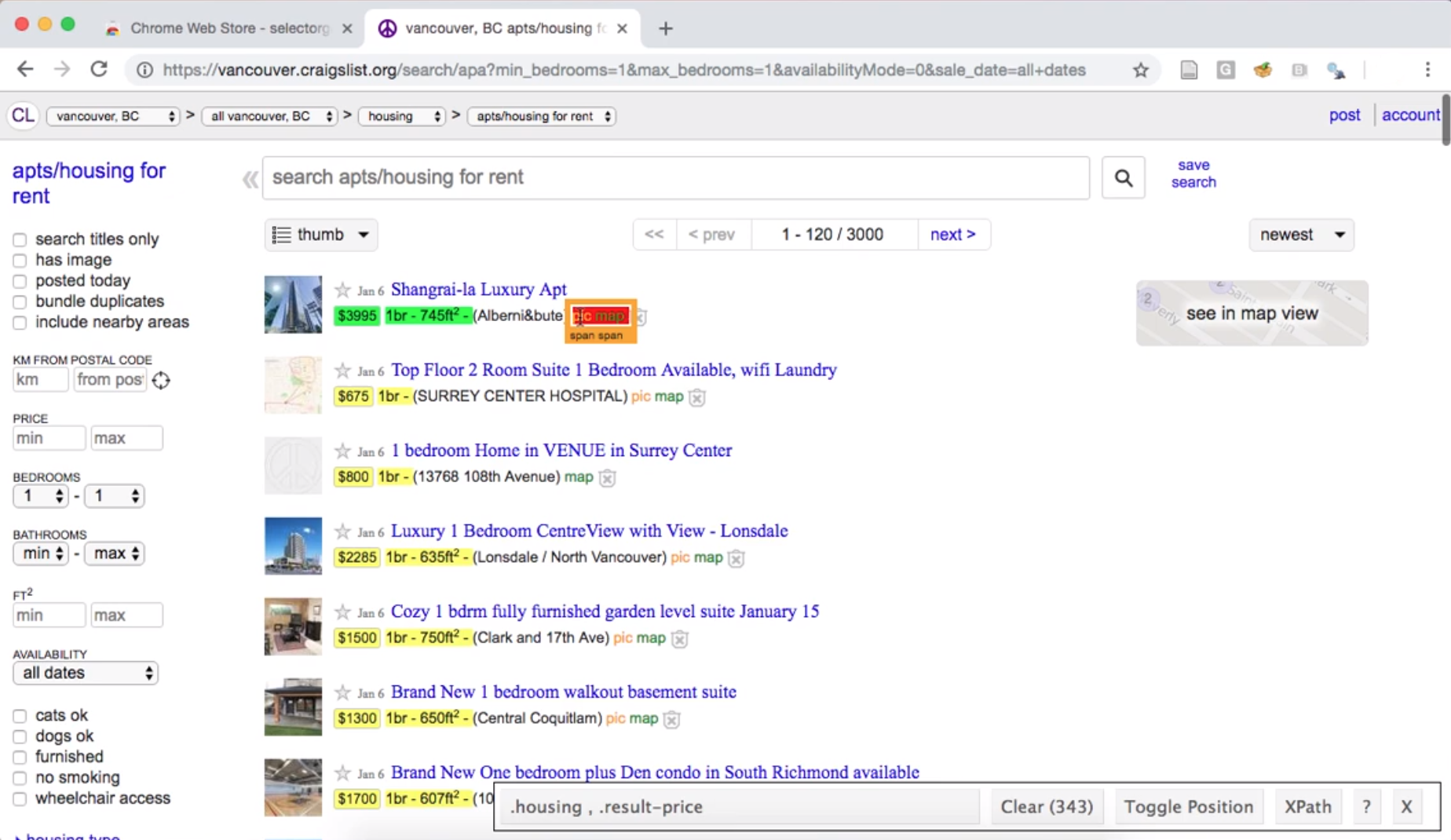
Figure 2.6: Using the SelectorGadget on a Craigslist webpage to refine the CCS selector to one that is most useful for obtaining apartment sizes.
So to scrape information about the square footage and rental price
of apartment listings, we need to use
the two CSS selectors .housing and .result-price, respectively.
The selector gadget returns them to us as a comma-separated list (here
.housing , .result-price), which is exactly the format we need to provide to
R if we are using more than one CSS selector.
Caution: are you allowed to scrape that website?
Before scraping data from the web, you should always check whether or not
you are allowed to scrape it! There are two documents that are important
for this: the robots.txt file and the Terms of Service
document. If we take a look at Craigslist’s Terms of Service document,
we find the following text: “You agree not to copy/collect CL content
via robots, spiders, scripts, scrapers, crawlers, or any automated or manual equivalent (e.g., by hand).”
So unfortunately, without explicit permission, we are not allowed to scrape the website.
What to do now? Well, we could ask the owner of Craigslist for permission to scrape. However, we are not likely to get a response, and even if we did they would not likely give us permission. The more realistic answer is that we simply cannot scrape Craigslist. If we still want to find data about rental prices in Vancouver, we must go elsewhere. To continue learning how to scrape data from the web, let’s instead scrape data on the population of Canadian cities from Wikipedia. We have checked the Terms of Service document, and it does not mention that web scraping is disallowed. We will use the SelectorGadget tool to pick elements that we are interested in (city names and population counts) and deselect others to indicate that we are not interested in them (province names), as shown in Figure 2.7.
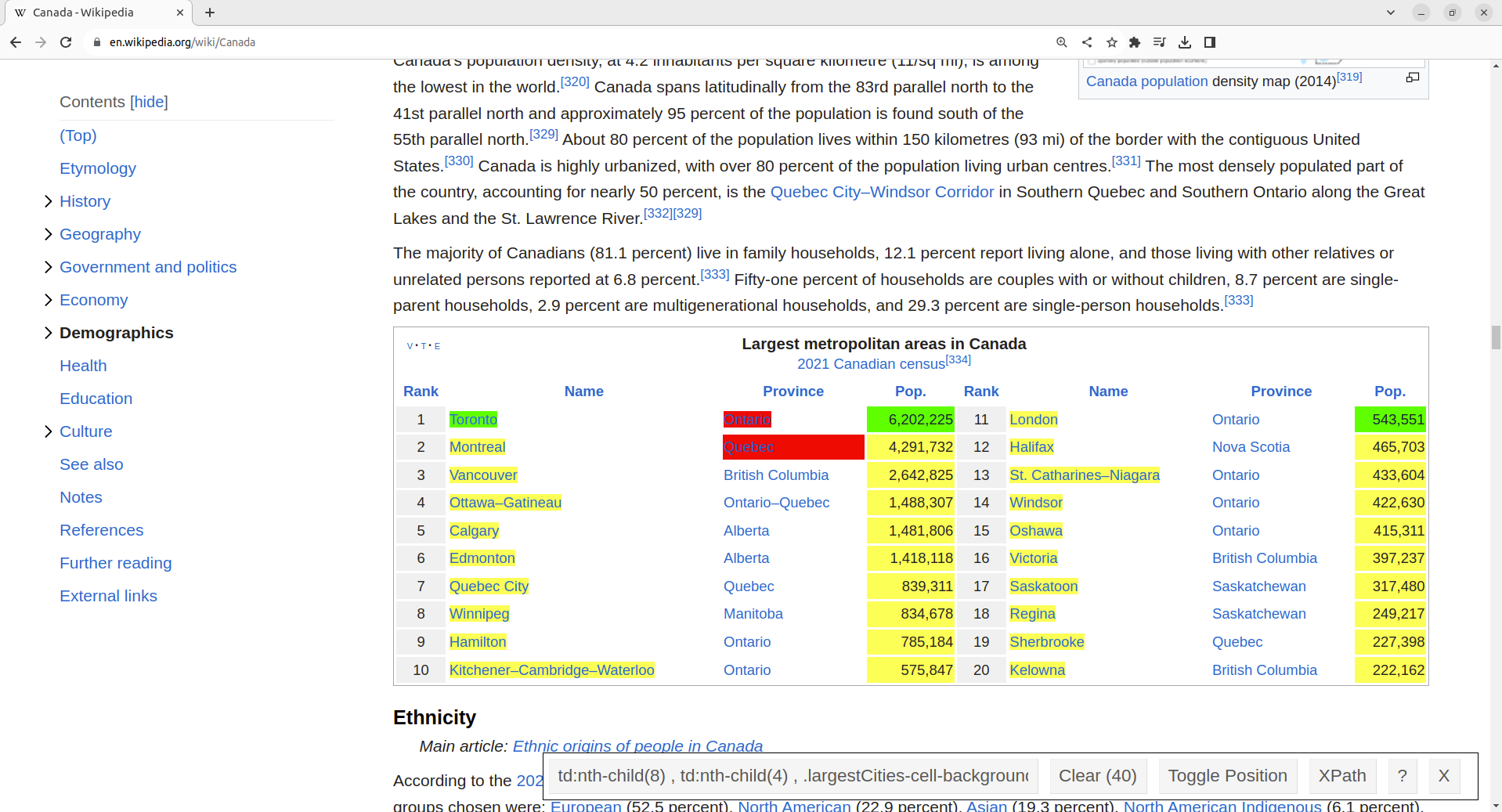
Figure 2.7: Using the SelectorGadget on a Wikipedia webpage.
We include a link to a short video tutorial on this process at the end of the chapter in the additional resources section. SelectorGadget provides in its toolbar the following list of CSS selectors to use:
td:nth-child(8) ,
td:nth-child(4) ,
.largestCities-cell-background+ td aNow that we have the CSS selectors that describe the properties of the elements that we want to target, we can use them to find certain elements in web pages and extract data.
Using rvest
We will use the rvest R package to scrape data from the Wikipedia page.
We start by loading the rvest package:
Next, we tell R what page we want to scrape by providing the webpage’s URL in quotations to the function read_html:
The read_html function directly downloads the source code for the page at
the URL you specify, just like your browser would if you navigated to that site. But
instead of displaying the website to you, the read_html function just returns
the HTML source code itself, which we have
stored in the page variable. Next, we send the page object to the html_nodes
function, along with the CSS selectors we obtained from
the SelectorGadget tool. Make sure to surround the selectors with quotation marks; the function, html_nodes, expects that
argument is a string. We store the result of the html_nodes function in the population_nodes variable.
Note that below we use the paste function with a comma separator (sep=",")
to build the list of selectors. The paste function converts
elements to characters and combines the values into a list. We use this function to
build the list of selectors to maintain code readability; this avoids
having a very long line of code.
selectors <- paste("td:nth-child(8)",
"td:nth-child(4)",
".largestCities-cell-background+ td a", sep = ",")
population_nodes <- html_nodes(page, selectors)
head(population_nodes)## {xml_nodeset (6)}
## [1] <a href="/wiki/Greater_Toronto_Area" title="Greater Toronto Area">Toronto ...
## [2] <td style="text-align:right;">6,202,225</td>
## [3] <a href="/wiki/London,_Ontario" title="London, Ontario">London</a>
## [4] <td style="text-align:right;">543,551\n</td>
## [5] <a href="/wiki/Greater_Montreal" title="Greater Montreal">Montreal</a>
## [6] <td style="text-align:right;">4,291,732</td>Note:
headis a function that is often useful for viewing only a short summary of an R object, rather than the whole thing (which may be quite a lot to look at). For example, hereheadshows us only the first 6 items in thepopulation_nodesobject. Note that some R objects by default print only a small summary. For example,tibbledata frames only show you the first 10 rows. But not all R objects do this, and that’s where theheadfunction helps summarize things for you.
Each of the items in the population_nodes list is a node from the HTML
document that matches the CSS selectors you specified. A node is an HTML tag
pair (e.g., <td> and </td> which defines the cell of a table) combined with
the content stored between the tags. For our CSS selector td:nth-child(4), an
example node that would be selected would be:
<td style="text-align:left;background:#f0f0f0;">
<a href="/wiki/London,_Ontario" title="London, Ontario">London</a>
</td>Next we extract the meaningful data—in other words, we get rid of the
HTML code syntax and tags—from the nodes using the html_text function.
In the case of the example node above, html_text function returns "London".
## [1] "Toronto" "6,202,225" "London" "543,551\n" "Montreal" "4,291,732"Fantastic! We seem to have extracted the data of interest from the
raw HTML source code. But we are not quite done; the data
is not yet in an optimal format for data analysis. Both the city names and
population are encoded as characters in a single vector, instead of being in a
data frame with one character column for city and one numeric column for
population (like a spreadsheet).
Additionally, the populations contain commas (not useful for programmatically
dealing with numbers), and some even contain a line break character at the end
(\n). In Chapter 3, we will learn more about how to wrangle data
such as this into a more useful format for data analysis using R.
2.8.2 Using an API
Rather than posting a data file at a URL for you to download, many websites these days
provide an API that must be accessed through a programming language like R. The benefit of using an API
is that data owners have much more control over the data they provide to users. However, unlike
web scraping, there is no consistent way to access an API across websites. Every website typically
has its own API designed especially for its own use case. Therefore we will just provide one example
of accessing data through an API in this book, with the hope that it gives you enough of a basic
idea that you can learn how to use another API if needed. In particular, in this book we will show you the basics
of how to use the httr2 package in R to access data from the NASA “Astronomy Picture
of the Day” API (a great source of desktop backgrounds, by the way—take a look at the stunning
picture of the Rho-Ophiuchi cloud complex (NASA et al. 2023) in Figure 2.8 from July 13, 2023!).

Figure 2.8: The James Webb Space Telescope’s NIRCam image of the Rho Ophiuchi molecular cloud complex.
First, you will need to visit the NASA APIs page and generate an API key (i.e., a password used to identify you when accessing the API). Note that a valid email address is required to associate with the key. The signup form looks something like Figure 2.9. After filling out the basic information, you will receive the token via email. Make sure to store the key in a safe place, and keep it private.
Figure 2.9: Generating the API access token for the NASA API
Caution: think about your API usage carefully!
When you access an API, you are initiating a transfer of data from a web server to your computer. Web servers are expensive to run and do not have infinite resources. If you try to ask for too much data at once, you can use up a huge amount of the server’s bandwidth. If you try to ask for data too frequently—e.g., if you make many requests to the server in quick succession—you can also bog the server down and make it unable to talk to anyone else. Most servers have mechanisms to revoke your access if you are not careful, but you should try to prevent issues from happening in the first place by being extra careful with how you write and run your code. You should also keep in mind that when a website owner grants you API access, they also usually specify a limit (or quota) of how much data you can ask for. Be careful not to overrun your quota! So before we try to use the API, we will first visit the NASA website to see what limits we should abide by when using the API. These limits are outlined in Figure 2.10.
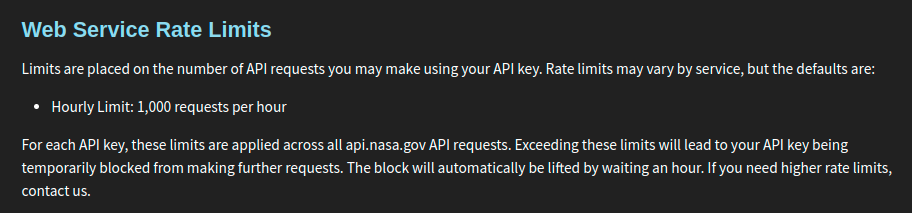
Figure 2.10: The NASA website specifies an hourly limit of 1,000 requests.
After checking the NASA website, it seems like we can send at most 1,000 requests per hour. That should be more than enough for our purposes in this section.
Accessing the NASA API
The NASA API is what is known as an HTTP API: this is a particularly common
kind of API, where you can obtain data simply by accessing a
particular URL as if it were a regular website. To make a query to the NASA
API, we need to specify three things. First, we specify the URL endpoint of
the API, which is simply a URL that helps the remote server understand which
API you are trying to access. NASA offers a variety of APIs, each with its own
endpoint; in the case of the NASA “Astronomy Picture of the Day” API, the URL
endpoint is https://api.nasa.gov/planetary/apod. Second, we write ?, which denotes that a
list of query parameters will follow. And finally, we specify a list of
query parameters of the form parameter=value, separated by & characters. The NASA
“Astronomy Picture of the Day” API accepts the parameters shown in
Figure 2.11.
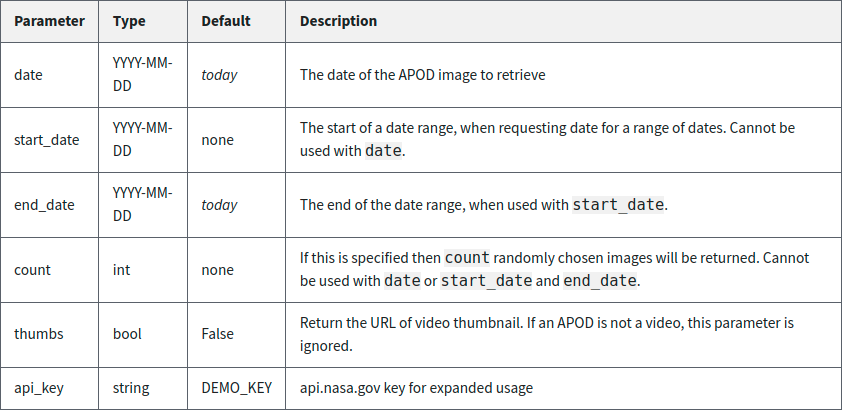
Figure 2.11: The set of parameters that you can specify when querying the NASA “Astronomy Picture of the Day” API, along with syntax, default settings, and a description of each.
So for example, to obtain the image of the day
from July 13, 2023, the API query would have two parameters: api_key=YOUR_API_KEY
and date=2023-07-13. Remember to replace YOUR_API_KEY with the API key you
received from NASA in your email! Putting it all together, the query will look like the following:
https://api.nasa.gov/planetary/apod?api_key=YOUR_API_KEY&date=2023-07-13If you try putting this URL into your web browser, you’ll actually find that the server responds to your request with some text:
{"date":"2023-07-13","explanation":"A mere 390 light-years away, Sun-like stars
and future planetary systems are forming in the Rho Ophiuchi molecular cloud
complex, the closest star-forming region to our fair planet. The James Webb
Space Telescope's NIRCam peered into the nearby natal chaos to capture this
infrared image at an inspiring scale. The spectacular cosmic snapshot was
released to celebrate the successful first year of Webb's exploration of the
Universe. The frame spans less than a light-year across the Rho Ophiuchi region
and contains about 50 young stars. Brighter stars clearly sport Webb's
characteristic pattern of diffraction spikes. Huge jets of shocked molecular
hydrogen blasting from newborn stars are red in the image, with the large,
yellowish dusty cavity carved out by the energetic young star near its center.
Near some stars in the stunning image are shadows cast by their protoplanetary
disks.","hdurl":"https://apod.nasa.gov/apod/image/2307/STScI-01_RhoOph.png",
"media_type":"image","service_version":"v1","title":"Webb's
Rho Ophiuchi","url":"https://apod.nasa.gov/apod/image/2307/STScI-01_RhoOph1024.png"}Neat! There is definitely some data there, but it’s a bit hard to
see what it all is. As it turns out, this is a common format for data called
JSON (JavaScript Object Notation).
We won’t encounter this kind of data much in this book,
but for now you can interpret this data as key : value pairs separated by
commas. For example, if you look closely, you’ll see that the first entry is
"date":"2023-07-13", which indicates that we indeed successfully received
data corresponding to July 13, 2023.
So now our job is to do all of this programmatically in R. We will load
the httr2 package, and construct the query using the request function, which takes a single URL argument;
you will recognize the same query URL that we pasted into the browser earlier.
We will then send the query using the req_perform function, and finally
obtain a JSON representation of the response using the resp_body_json function.
library(httr2)
req <- request("https://api.nasa.gov/planetary/apod?api_key=YOUR_API_KEY&date=2023-07-13")
resp <- req_perform(req)
nasa_data_single <- resp_body_json(resp)
nasa_data_single## $date
## [1] "2023-07-13"
##
## $explanation
## [1] "A mere 390 light-years away, Sun-like stars and future planetary systems are forming in the Rho Ophiuchi molecular cloud complex, the closest star-forming region to our fair planet. The James Webb Space Telescope's NIRCam peered into the nearby natal chaos to capture this infrared image at an inspiring scale. The spectacular cosmic snapshot was released to celebrate the successful first year of Webb's exploration of the Universe. The frame spans less than a light-year across the Rho Ophiuchi region and contains about 50 young stars. Brighter stars clearly sport Webb's characteristic pattern of diffraction spikes. Huge jets of shocked molecular hydrogen blasting from newborn stars are red in the image, with the large, yellowish dusty cavity carved out by the energetic young star near its center. Near some stars in the stunning image are shadows cast by their protoplanetary disks."
##
## $hdurl
## [1] "https://apod.nasa.gov/apod/image/2307/STScI-01_RhoOph.png"
##
## $media_type
## [1] "image"
##
## $service_version
## [1] "v1"
##
## $title
## [1] "Webb's Rho Ophiuchi"
##
## $url
## [1] "https://apod.nasa.gov/apod/image/2307/STScI-01_RhoOph1024.png"We can obtain more records at once by using the start_date and end_date parameters, as
shown in the table of parameters in 2.11.
Let’s obtain all the records between May 1, 2023, and July 13, 2023, and store the result
in an object called nasa_data; now the response
will take the form of an R list (you’ll learn more about these in Chapter 3).
Each item in the list will correspond to a single day’s record (just like the nasa_data_single object),
and there will be 74 items total, one for each day between the start and end dates:
req <- request("https://api.nasa.gov/planetary/apod?api_key=YOUR_API_KEY&start_date=2023-05-01&end_date=2023-07-13")
resp <- req_perform(req)
nasa_data <- resp_body_json(response)
length(nasa_data)## [1] 74For further data processing using the techniques in this book, you’ll need to turn this list of items
into a data frame. Here we will extract the date, title, copyright, and url variables
from the JSON data, and construct a data frame using the extracted information.
Note: Understanding this code is not required for the remainder of the textbook. It is included for those readers who would like to parse JSON data into a data frame in their own data analyses.
nasa_df_all <- tibble(bind_rows(lapply(nasa_data, as.data.frame.list)))
nasa_df <- select(nasa_df_all, date, title, copyright, url)
nasa_df## # A tibble: 74 × 4
## date title copyright url
## <chr> <chr> <chr> <chr>
## 1 2023-05-01 Carina Nebula North "\nCarlos Tayl… http…
## 2 2023-05-02 Flat Rock Hills on Mars "\nNASA, \nJPL… http…
## 3 2023-05-03 Centaurus A: A Peculiar Island of Stars "\nMarco Loren… http…
## 4 2023-05-04 The Galaxy, the Jet, and a Famous Black Hole <NA> http…
## 5 2023-05-05 Shackleton from ShadowCam <NA> http…
## 6 2023-05-06 Twilight in a Flower "Dario Giannob… http…
## 7 2023-05-07 The Helix Nebula from CFHT <NA> http…
## 8 2023-05-08 The Spanish Dancer Spiral Galaxy <NA> http…
## 9 2023-05-09 Shadows of Earth "\nMarcella Gi… http…
## 10 2023-05-10 Milky Way over Egyptian Desert "\nAmr Abdulwa… http…
## # ℹ 64 more rowsSuccess—we have created a small data set using the NASA
API! This data is also quite different from what we obtained from web scraping;
the extracted information is readily available in a JSON format, as opposed to raw
HTML code (although not every API will provide data in such a nice format).
From this point onward, the nasa_df data frame is stored on your
machine, and you can play with it to your heart’s content. For example, you can use
write_csv to save it to a file and read_csv to read it into R again later;
and after reading the next few chapters you will have the skills to
do even more interesting things! If you decide that you want
to ask any of the various NASA APIs for more data
(see the list of awesome NASA APIS here
for more examples of what is possible), just be mindful as usual about how much
data you are requesting and how frequently you are making requests.
2.9 Exercises
Practice exercises for the material covered in this chapter can be found in the accompanying worksheets repository in the “Reading in data locally and from the web” row. You can launch an interactive version of the worksheet in your browser by clicking the “launch binder” button. You can also preview a non-interactive version of the worksheet by clicking “view worksheet.” If you instead decide to download the worksheet and run it on your own machine, make sure to follow the instructions for computer setup found in Chapter 13. This will ensure that the automated feedback and guidance that the worksheets provide will function as intended.
2.10 Additional resources
- The
readrdocumentation provides the documentation for many of the reading functions we cover in this chapter. It is where you should look if you want to learn more about the functions in this chapter, the full set of arguments you can use, and other related functions. The site also provides a very nice cheat sheet that summarizes many of the data wrangling functions from this chapter. - Sometimes you might run into data in such poor shape that none of the reading functions we cover in this chapter work. In that case, you can consult the data import chapter from R for Data Science (Wickham and Grolemund 2016), which goes into a lot more detail about how R parses text from files into data frames.
- The
hereR package (Müller 2020) provides a way for you to construct or find your files’ paths. - The
readxldocumentation provides more details on reading data from Excel, such as reading in data with multiple sheets, or specifying the cells to read in. - The
rioR package (Leeper 2021) provides an alternative set of tools for reading and writing data in R. It aims to be a “Swiss army knife” for data reading/writing/converting, and supports a wide variety of data types (including data formats generated by other statistical software like SPSS and SAS). - A video from the Udacity course Linux Command Line Basics provides a good explanation of absolute versus relative paths.
- If you read the subsection on obtaining data from the web via scraping and APIs, we provide two companion tutorial video links for how to use the SelectorGadget tool to obtain desired CSS selectors for:
- The
politeR package (Perepolkin 2021) provides a set of tools for responsibly scraping data from websites.