 Data Science
Data SciencePreface
This textbook aims to be an approachable introduction to the world of data science. In this book, we define data science as the process of generating insight from data through reproducible and auditable processes. If you analyze some data and give your analysis to a friend or colleague, they should be able to re-run the analysis from start to finish and get the same result you did (reproducibility). They should also be able to see and understand all the steps in the analysis, as well as the history of how the analysis developed (auditability). Creating reproducible and auditable analyses allows both you and others to easily double-check and validate your work.
At a high level, in this book, you will learn how to
- identify common problems in data science, and
- solve those problems with reproducible and auditable workflows.
Figure 0.1 summarizes what you will learn in each chapter of this book. Throughout, you will learn how to use the R programming language (R Core Team 2021) to perform all the tasks associated with data analysis. You will spend the first four chapters learning how to use R to load, clean, wrangle (i.e., restructure the data into a usable format) and visualize data while answering descriptive and exploratory data analysis questions. In the next six chapters, you will learn how to answer predictive, exploratory, and inferential data analysis questions with common methods in data science, including classification, regression, clustering, and estimation. In the final chapters (11–13), you will learn how to combine R code, formatted text, and images in a single coherent document with Jupyter, use version control for collaboration, and install and configure the software needed for data science on your own computer. If you are reading this book as part of a course that you are taking, the instructor may have set up all of these tools already for you; in this case, you can continue on through the book reading the chapters in order. But if you are reading this independently, you may want to jump to these last three chapters early before going on to make sure your computer is set up in such a way that you can try out the example code that we include throughout the book.
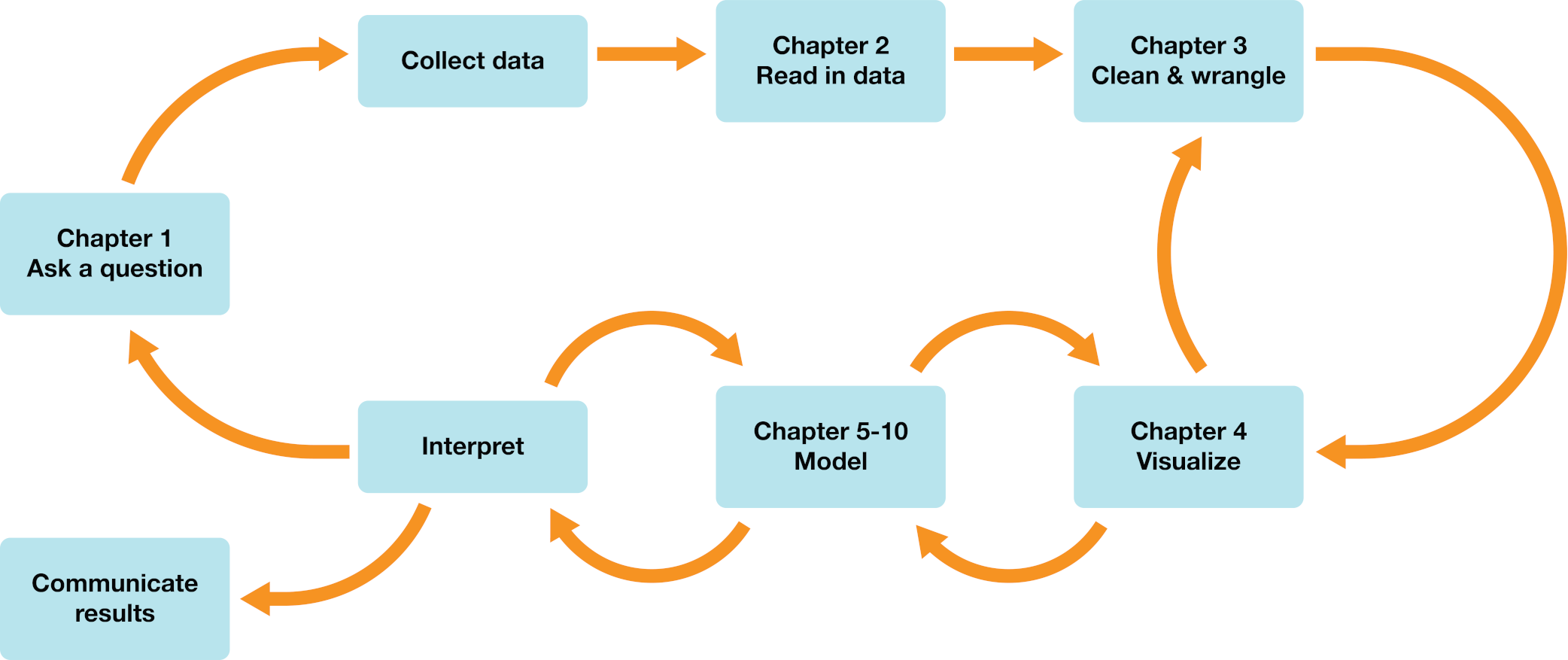
Figure 0.1: Where are we going?
Each chapter in the book has an accompanying worksheet that provides exercises to help you practice the concepts you will learn. We strongly recommend that you work through the worksheet when you finish reading each chapter before moving on to the next chapter. All of the worksheets are available at https://worksheets.datasciencebook.ca; the “Exercises” section at the end of each chapter points you to the right worksheet for that chapter. For each worksheet, you can either launch an interactive version of the worksheet in your browser by clicking the “launch binder” button, or preview a non-interactive version of the worksheet by clicking “view worksheet.” If you instead decide to download the worksheet and run it on your own machine, make sure to follow the instructions for computer setup found in Chapter 13. This will ensure that the automated feedback and guidance that the worksheets provide will function as intended.